Setting
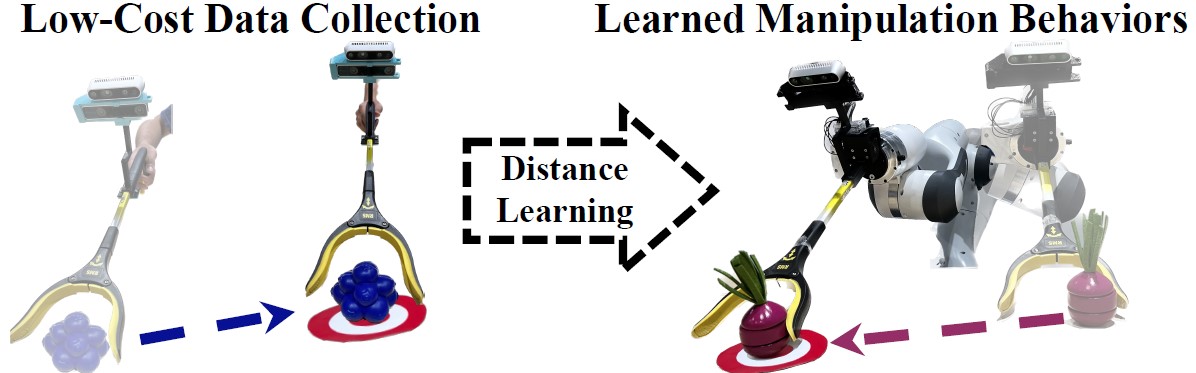
Our system: In our problem setting we use a low-cost reacher grabber tool (left) to collect training demonstrations. These demonstrations are used to acquire a robot controller purely through distance/representation learning. The final system is deployed on a robot (right) to solve various tasks at test-time.
Training
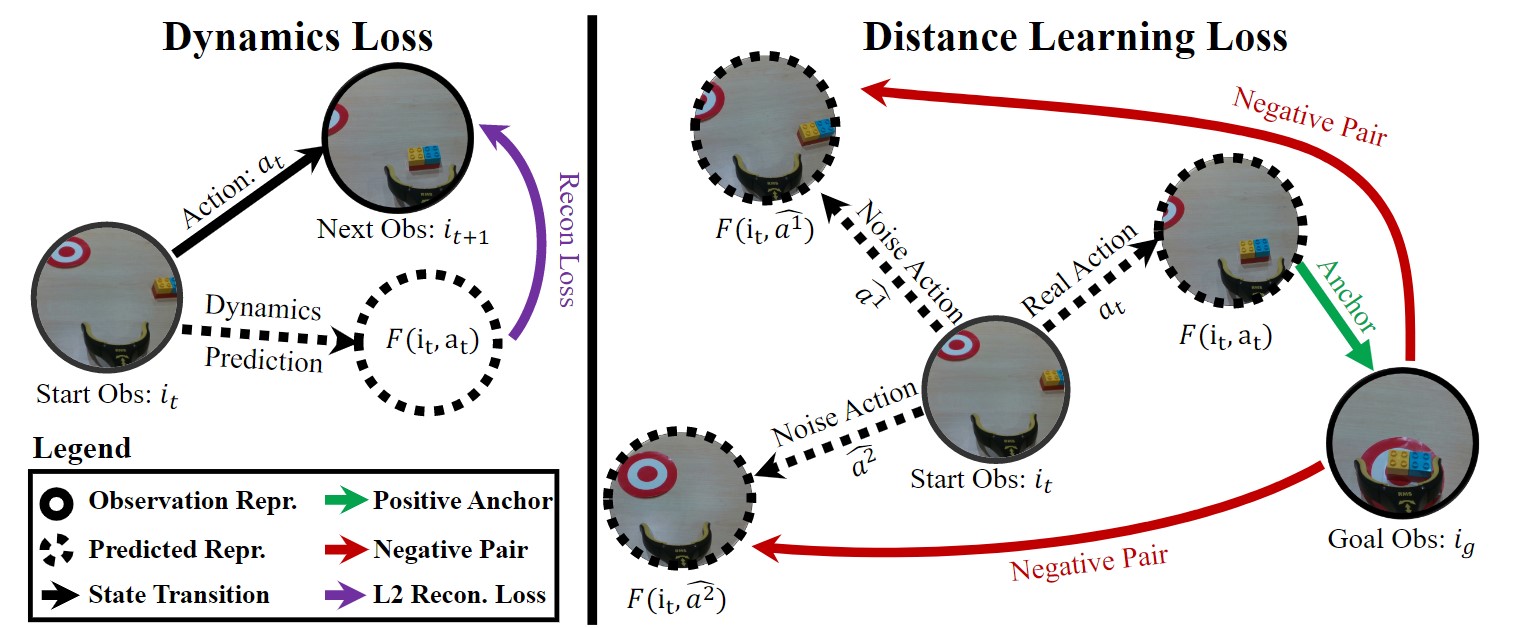
Our method leverages a pre-trained representation network, R, to encode observations, it = R(It), and enables control via distance learning. Specifically, we use contrastive representation learning methods to learn a distance metric, d(ij, ik), on the pre-trained embedding space. The key idea is to use this distance metric to select which of the possible future state is closest to the goal state. But how do we predict possible future states? We explicitly learn a dynamics function, F(it, at) that predicts future state for a possible action at. During test time, we predict multiple future states using different possible action and select the one which is closes to goal state.
Testing

Given the distance function and dynamics model, our inference procedure is as simple as choosing the action that minimizes the distance to the goal state. More concretely, initialize from a beginning state and given a goal image. We consider a set of candidate actions at each step. The learned distance predictor then infers the future distance corresponding to all these candidates, and we execute the action with the lowest predicted distance-to-goal. We repeat this procedure until reaching sufficiently close to the desired goal.